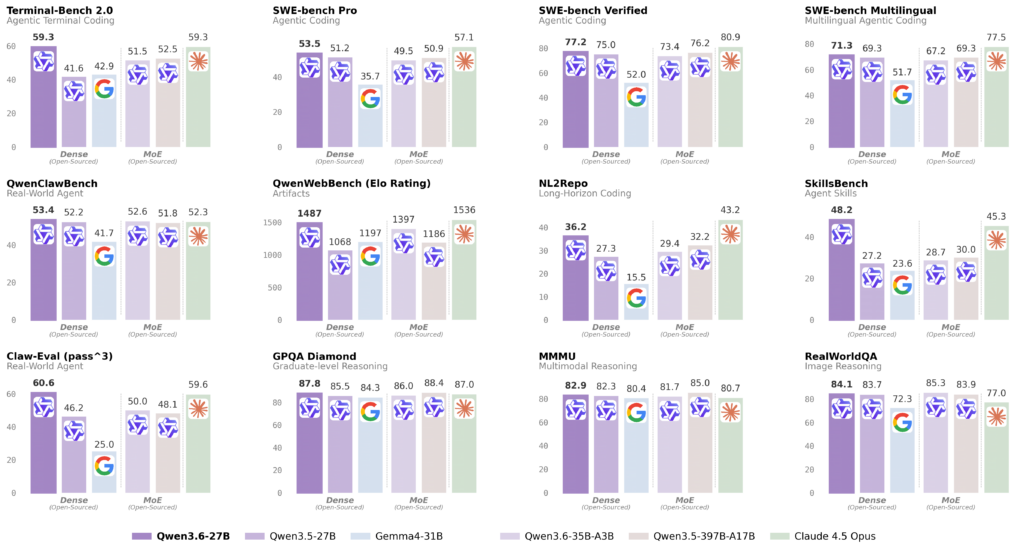
Qwen3.6-27B is a 27B dense model that outperforms a 397B on coding benchmarks
Alibaba’s Qwen team just released Qwen3.6-27B, a dense 27-billion-parameter open-weight model under Apache 2.0 that beats the much larger Qwen3.5-397B on agentic coding benchmarks.
Alibaba’s Qwen team just released Qwen3.6-27B, a dense 27-billion-parameter open-weight model available under the Apache 2.0 license. It runs locally, supports fine-tuning, and carries no commercial restrictions.
Qwen models have a history of punching above their weight class on benchmarks. Qwen3.6-27B continues that pattern, this time beating the much larger Qwen3.5-397B-A17B on several agentic coding tests despite having a fraction of the total parameters.
On SWE-bench Verified, Qwen3.6-27B scores 77.2 against the larger model’s 76.2. The gap widens on other benchmarks:
- SWE-bench Pro: 53.5 vs. 50.9
- Terminal-Bench 2.0: 59.3 vs. 52.5
- SkillsBench: 48.2 vs. 30.0
The model supports text, image, and video understanding natively through an integrated vision encoder. A single checkpoint covers both thinking and non-thinking modes, with a preserve_thinking option for agent workflows that need the full reasoning trace.
On the technical side:
- Native context window: 262K tokens, extendable to roughly 1M via YaRN
- Local hardware: Designed to run quantized on a single high-end GPU
- License: Apache 2.0, with no restrictions on commercial use or fine-tuning
The Qwen3.6-27B follows the Qwen3.6-35B-A3B, a MoE variant with 35B total and 3B active parameters released about five days ago. Alibaba also offers closed variants under the Qwen3.6 family, including Qwen3.6-Plus and the newer Qwen3.6-Max-Preview.
Bottom line Local models are not at the same level as the top proprietary ones, but they are getting more capable fast. A dense 27B model clearing these benchmarks on a single GPU is good news for anyone running AI locally.
Source: Qwen
Get the core business tech news delivered straight to your inbox. We track AI, automation, SaaS, and cybersecurity so you don't have to.
Just read what you want, and be done with it.