A 12 million token LLM appeared out of nowhere, and the AI community isn’t sure what to make of it
A new AI company called Subquadratic just launched SubQ, claiming a 12 million token context window at a fraction of the cost of leading models. The community is skeptical.
Subquadratic just launched SubQ, its first model, claiming a 12 million token context window, costs under 5% of Claude Opus, and prefill speeds 52 times faster than the current baseline at 1 million tokens. The company raised a $29M seed round and is opening early API access today at subq.ai.
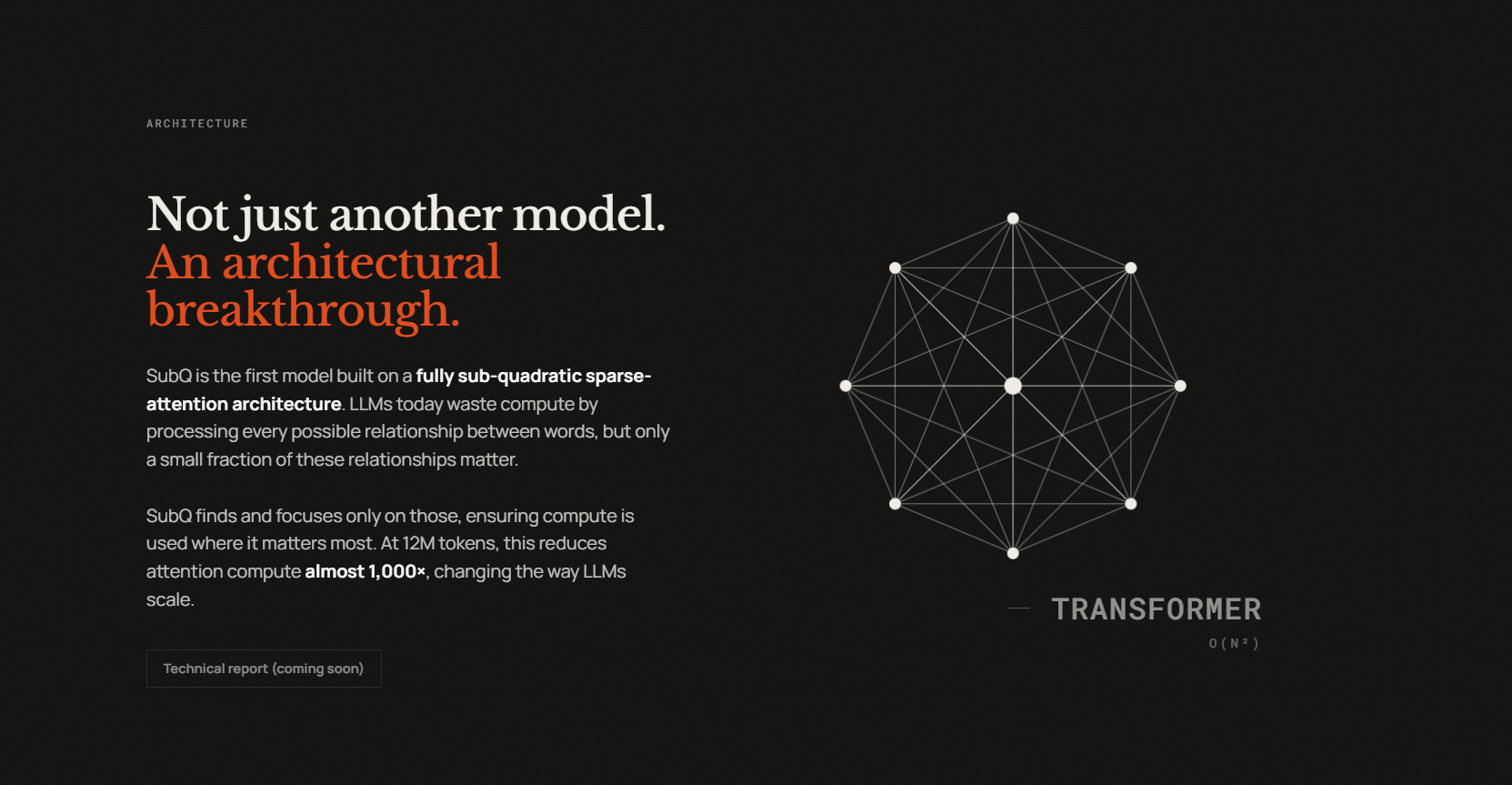
The company says its model is built on a different architecture compared to other models. Every major AI model today processes each token in a conversation against every other token, which gets exponentially more expensive as context grows. At 1 million tokens it becomes impractical; at 12 million it is essentially impossible for most labs.
Subquadratic says its sparse-attention architecture sidesteps that by only computing relationships between tokens that are actually relevant to a given query, skipping the rest. The result, if the claims hold, is that compute scales linearly instead of exponentially.
The benchmark numbers the company is leading with:
- SWE-Bench Verified: 81.8%, ahead of Gemini 3.1 Pro (80.6%) and Claude Opus 4.6 (80.8%), but behind Opus 4.7 at 87.6%
- RULER @ 128K: 95.0%, marginally ahead of Opus 4.6 at 94.8%
- MRCR v2 (8-needle, 1M): 65.9% in the production variant, behind Opus 4.6 at 78.3% and GPT 5.5 at 74%
That last result is worth pausing on. The benchmark most directly tied to the company’s core long-context claim is the one where SubQ trails the competition in production. Subquadratic cites a research variant scoring 83 on the same test, but that number is not what ships.
The community reaction has been a mix of genuine excitement and hard skepticism. The announcement pulled over 5 million views on X within hours. The pushback came just as fast.
The main concerns circulating:
- Funding math: Critics note that $29M is implausible for training a true from-scratch frontier model at the scale needed to rival Opus or GPT 5.5 on coding benchmarks. The suspicion is that SubQ is built on top of an existing model rather than trained purely from scratch
- Benchmark selection: The company advertises 12M token capability but all public benchmarks are for the SubQ 1M-Preview variant. RULER is shown only at 128K, well below the advertised ceiling
- No technical report yet: The full report is listed as coming soon. Without it, the architectural claims around linear scaling cannot be independently verified
- Known tradeoffs: Sparse attention is not a new idea. Prior attempts, including variants from DeepSeek and others, have underdelivered on reliable long-context reasoning despite strong synthetic benchmark results. Critics including former OpenAI researchers have flagged that a sparse router can miss critical long-range dependencies in ways that only surface on messy real-world data

The company was founded by Justin Dangel and Alexander Whedon, whose background includes leading generative AI implementations at TribeAI. The research team lists affiliations from Meta, Google, Oxford, Cambridge, and ByteDance. Investors include early backers from Anthropic, OpenAI, Stripe, and Brex.
Two products are available for early access alongside the API. SubQ Code is a plug-in coding agent that routes expensive context-heavy turns through SubQ instead of a primary model, claiming around 25% lower costs and faster codebase exploration. SubQ Search adds long-context deep research at what the company describes as chatbot speed.
Bottom line: The architecture, if it delivers what Subquadratic claims, would remove one of the main cost constraints on long-context agents. But the technical report is not out, the production benchmark on the most relevant long-context test trails the competition, and the community is in wait-and-see mode. Early access results will matter more than the launch numbers.
Source: Subquadratic
Get the core business tech news delivered straight to your inbox. We track AI, automation, SaaS, and cybersecurity so you don't have to.
Just read what you want, and be done with it.



