NVIDIA releases Nemotron-Cascade 2 to rival Chinese open-source models
NVIDIA just launched Nemotron-Cascade 2, a highly efficient open-weight reasoning model. The release is a direct challenge the recent dominance of Chinese open-source models.

NVIDIA just released Nemotron-Cascade-2-30B-A3B, its latest open-weight Mixture-of-Experts (MoE) model. The release provides developers with a highly efficient alternative to leading Chinese open-source models like Alibaba’s Qwen.
- The architecture: The model contains 30 billion total parameters but only activates 3 billion parameters per generated token.
- The training: NVIDIA used a post-training method called Cascade RL alongside multi-domain on-policy distillation.
- The availability: The model weights, training data, and technical report are available under an open license on Hugging Face.
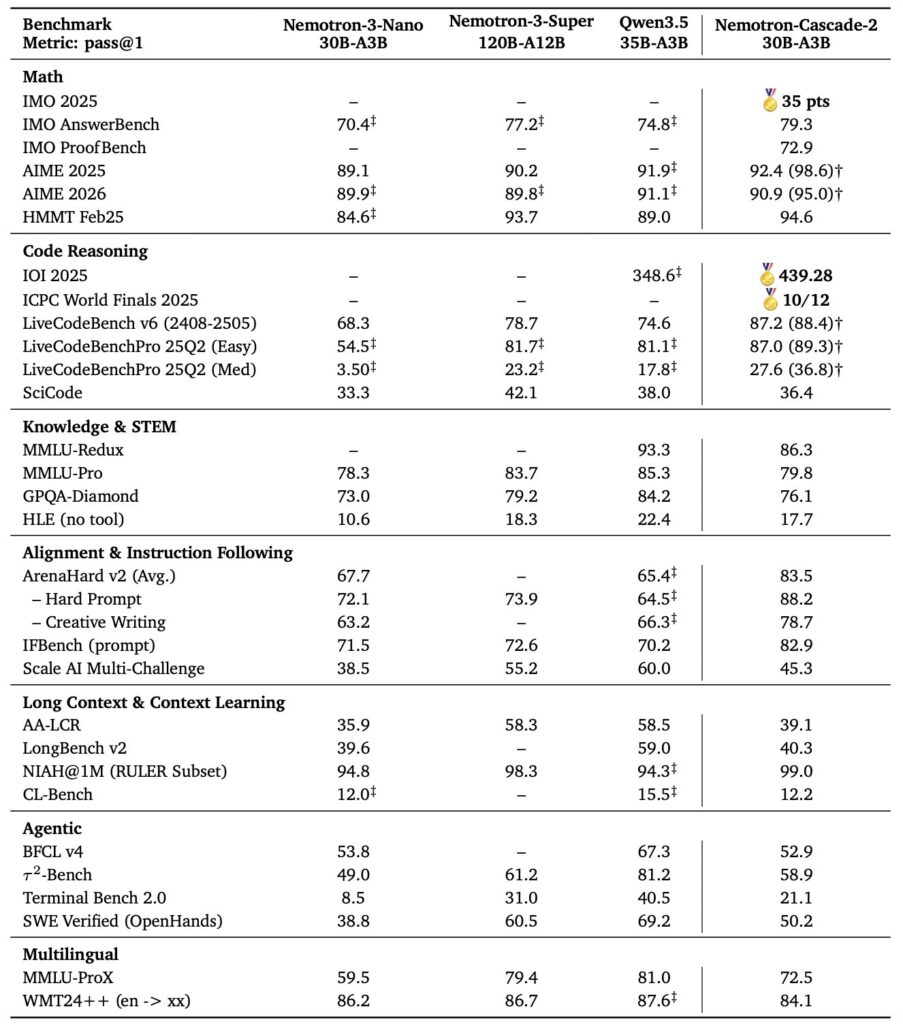
Nemotron-Cascade 2 reportedly outperforms much larger systems, including the 122-billion parameter Qwen3.5, across complex mathematics, coding evaluations, and agentic workflows. However, these benchmarks are self-reported by NVIDIA, and the developer community has yet to verify its actual real-world performance.
- Math and coding: It achieved a 79.3 percent pass rate on the rigorous IMO 2025 benchmark and scored 439 points on IOI 2025.
- Agentic performance: The model scored 21.1 percent on TerminalBench 2.0, demonstrating strong capabilities in software repair tasks.
Because the model only relies on 3 billion active parameters, developers can run it locally on standard consumer graphics cards instead of requiring expensive datacenter servers.
- Standard consumer hardware: Quantizing the model to 4-bit allows it to fit comfortably on a single 24 GB card like the RTX 4090 or RTX 5090.
- Minimal footprint: Using aggressive 2-bit or 3-bit quantization reduces the VRAM requirement down to 16 GB with a minor drop in output quality.
- Full precision: Running the uncompressed model requires 55 to 65 GB of VRAM, making dual 24 GB cards or a single datacenter GPU the ideal setup.
The Bottom Line: NVIDIA is betting big on these highly efficient, low-parameter architectures to compete directly with Chinese open-source models.
Get the core business tech news delivered straight to your inbox. We track AI, automation, SaaS, and cybersecurity so you don't have to.
Just read what you want, and be done with it.