Google’s TurboQuant compresses AI memory by 6x without losing accuracy
Google just found a way to compress AI memory by 6x with zero quality loss — meaning longer conversations, faster responses, and cheaper inference on the same hardware.
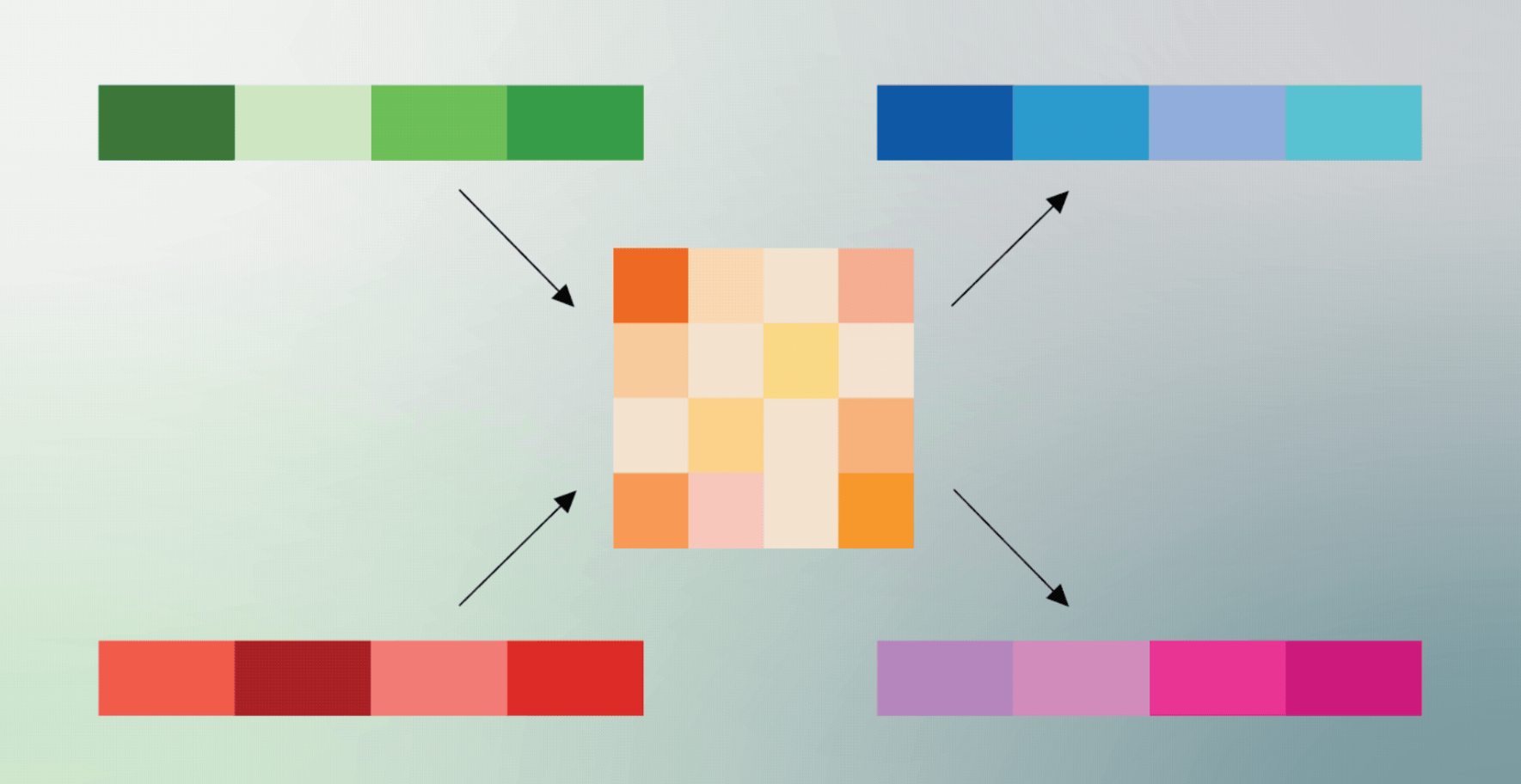
One of the quieter bottlenecks in AI is memory. Every time you have a conversation with an AI model, it has to keep track of everything said earlier in that conversation. The longer the conversation, the more memory it needs. At scale, that memory becomes expensive, slow, and a hard ceiling on how much context a model can handle at once.
Google Research published TurboQuant yesterday, a new compression algorithm that shrinks that memory by at least 6x while delivering up to 8x faster processing. At 3.5 bits per value, output quality is essentially identical to full precision. Push it further to 2.5 bits and there is only marginal degradation.
- What it means in practice: Models can handle much longer conversations on the same hardware. Tasks that required expensive server infrastructure could run on a laptop or phone.
- The speed gain: Up to 8x faster attention computation on current hardware, which translates directly to lower latency and cheaper inference costs.
- The accuracy claim: Independently validated within hours of publication. A developer tested it on a 35-billion parameter model and reported exact matches against full-precision output at both compression levels tested.
The reason most compression techniques sacrifice quality is that they introduce rounding errors that accumulate over time. TurboQuant uses a two-stage approach that mathematically corrects for those errors before they compound, hitting near-theoretical limits on how much you can compress without distortion.
It requires no retraining or fine-tuning of existing models. It works on top of whatever is already running.
The local AI community reacted immediately. Within hours of the announcement, developers were already porting it to Apple Silicon, where memory has always been the main constraint for running large models locally.
The Bottom Line: Most AI efficiency announcements involve a trade-off somewhere. This one does not appear to. Faster, smaller, cheaper, same quality — and it drops straight into existing inference pipelines without modification.
The open-source saviour?
The implications for open source models are worth spelling out. Right now, the main reason most people cannot run a large open source model locally is memory. A model like MiniMax or Qwen at full size simply requires more RAM than a standard laptop or phone has available. The KV cache is a significant part of that constraint.
A 6x reduction changes the math considerably. Models that previously required a high-end workstation become viable on a MacBook. Models that required a MacBook could potentially run on a phone. The gap between what you can access through a paid cloud API and what you can run privately on your own hardware has been closing steadily over the past two years — TurboQuant could push that gap closer faster than most people expected.
- Why open source specifically: Proprietary models like GPT or Gemini run on Google and OpenAI infrastructure, so efficiency gains there lower costs for the company. For open source models, the same gains lower the barrier for every individual user running the model themselves.
- No retraining required: This works on existing open source models without modification, meaning the entire current library of publicly available models benefits immediately.
- Worth noting: TurboQuant compresses the memory models use during conversation, not the model weights themselves. Very large models still require significant storage to load in the first place — but for mid-size open source models already within reach of consumer hardware, this closes the gap meaningfully.
The Bottom Line: A lot of people in the AI community believe open source needs to win. If TurboQuant delivers on what the early tests suggest, we might be closer to that than anyone expected — and the irony is that the push came from Google, one of the very companies open source developers are fighting against.
Source: Google Research
Get the core business tech news delivered straight to your inbox. We track AI, automation, SaaS, and cybersecurity so you don't have to.
Just read what you want, and be done with it.