Google announces Gemini 3.1 Flash Live to power AI agents
Google just released Gemini 3.1 Flash Live. It eliminates awkward pauses and is heavily optimized for developers building autonomous AI agents.

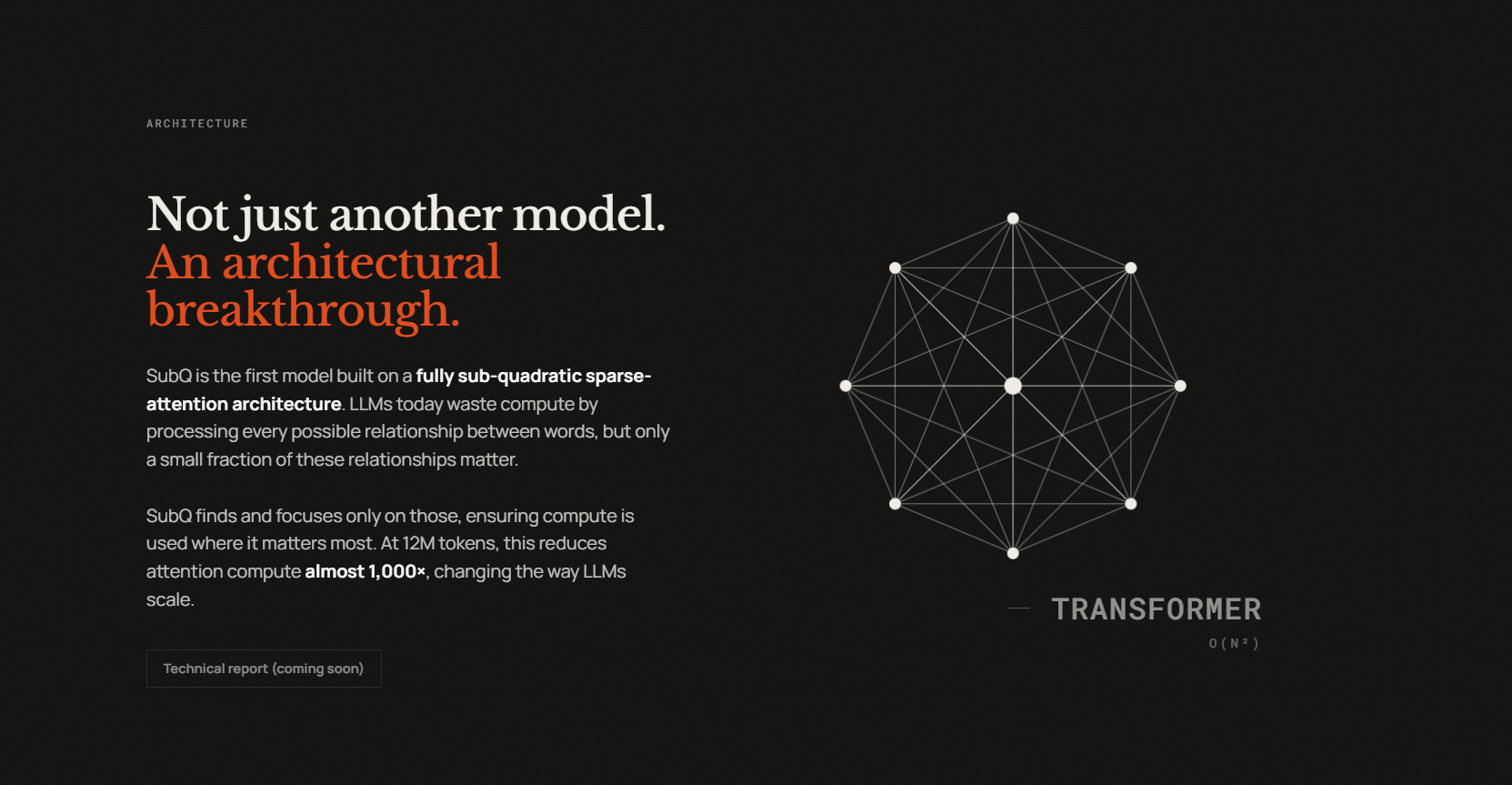
Google just unveiled Gemini 3.1 Flash Live today. This new model acts as the company’s highest-quality audio system for natural, low-latency conversations.
Google’s goal with this release was to eliminate awkward pauses and process multi-modal streams seamlessly across both consumer apps and enterprise platforms.
- Faster responses: The system significantly reduces latency and dynamically adjusts its tone based on the user’s emotional state.
- Extended memory: The AI maintains conversation threads for twice as long. Users no longer need to repeat earlier details during complex tasks.
- Environmental filtering: The architecture effectively separates relevant human speech from background interference like passing traffic or televisions.
- Global reach: The model inherently supports over 90 languages. This native capability powers the immediate global expansion of the Search Live feature to more than 200 countries.
Beyond basic consumer searches, the entire point of this release is to provide an infrastructure for autonomous AI agents. Developers can now embed a highly optimized, human-like voice directly into their own applications without dealing with traditional transcription delays.
- The architecture: The system builds on a Gemini 3 Pro foundation. It supports a 128K token context window for audio, image, and video inputs.
- API access: Developers can immediately test the new preview endpoint through the Gemini Live API in Google AI Studio.
- Enterprise agents: Companies can deploy the model through Vertex AI. This allows businesses to build customer service agents capable of complex tool execution and multi-step reasoning in noisy environments.
Bottom line: Gemini 3.1 Flash Live is heavily optimized for agentic workflows. If you are building an interactive AI tool, this is the low-latency voice model you need to embed.
Check out the Gemini 3.1 Flash Live model card.
Get the core business tech news delivered straight to your inbox. We track AI, automation, SaaS, and cybersecurity so you don't have to.
Just read what you want, and be done with it.