Cheaper AI models often cost more to run than expensive ones, new research finds
New research shows that in over 1 in 5 comparisons, the cheaper AI model actually costs more to run. The culprit is a cost that most providers do not clearly surface.

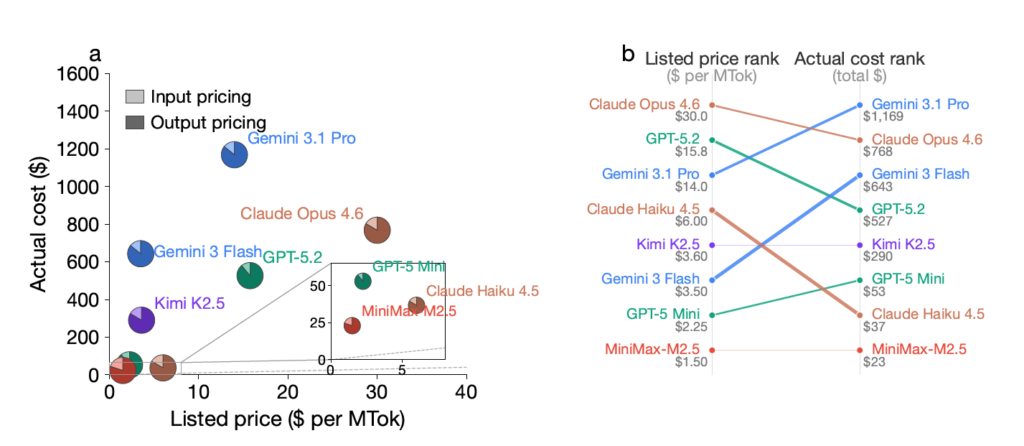
A new paper studied eight frontier reasoning models and found something that should give any developer pause. In 21.8% of direct comparisons, the model with the lower listed price ended up costing more in actual usage.
The researchers call these “pricing reversals.” They are not edge cases.
The most concrete example in the paper: Gemini 3 Flash is listed at 78% cheaper than GPT-5.2. Across all evaluated tasks, it ended up 22% more expensive. In the most extreme cases across all model pairs, the actual cost was up to 28 times higher than listed prices suggested.
The cause is thinking tokens.
Reasoning models generate internal “thinking tokens” as they work through a problem before producing a response. These tokens are billed at the same rate as output tokens but are not always clearly visible to the user. Different models consume vastly different amounts of them for the exact same query.
- The variance: Across all tasks, Claude Opus 4.6 used 24.2 million thinking tokens. Gemini 3 Flash used 208 million — for the same problems.
- The proof: When researchers removed thinking token costs from their calculations, pricing reversals dropped by 70%.
- The unpredictability: Running the same prompt on the same model multiple times produced up to 9.7 times difference in cost between the cheapest and most expensive execution.
That last point is the most uncomfortable one for anyone trying to budget AI costs. The model’s internal reasoning path is not predictable from prompt length. Simple cost estimation methods do not work.
- For developers: API pricing pages are not a reliable basis for model selection. Testing your actual workload with representative queries is the only way to know what you will spend.
- For providers: The researchers advocate for exposing expected thinking overhead and providing per-request cost monitoring.
- For benchmarks: Inference cost should be treated as a primary performance metric alongside accuracy, not an afterthought.
The researchers published code for auditing thinking token usage alongside the paper.
Bottom line: Picking a model based on listed price without testing your actual workload is essentially guessing. What sounds like a great deal on paper, might end up being a more expensive option in the long run. Choose your models based on the pre-planned workloads.
Source: Arxiv
Get the core business tech news delivered straight to your inbox. We track AI, automation, SaaS, and cybersecurity so you don't have to.
Just read what you want, and be done with it.