AI models are starting to read floor plans from photos, but humans are still far ahead
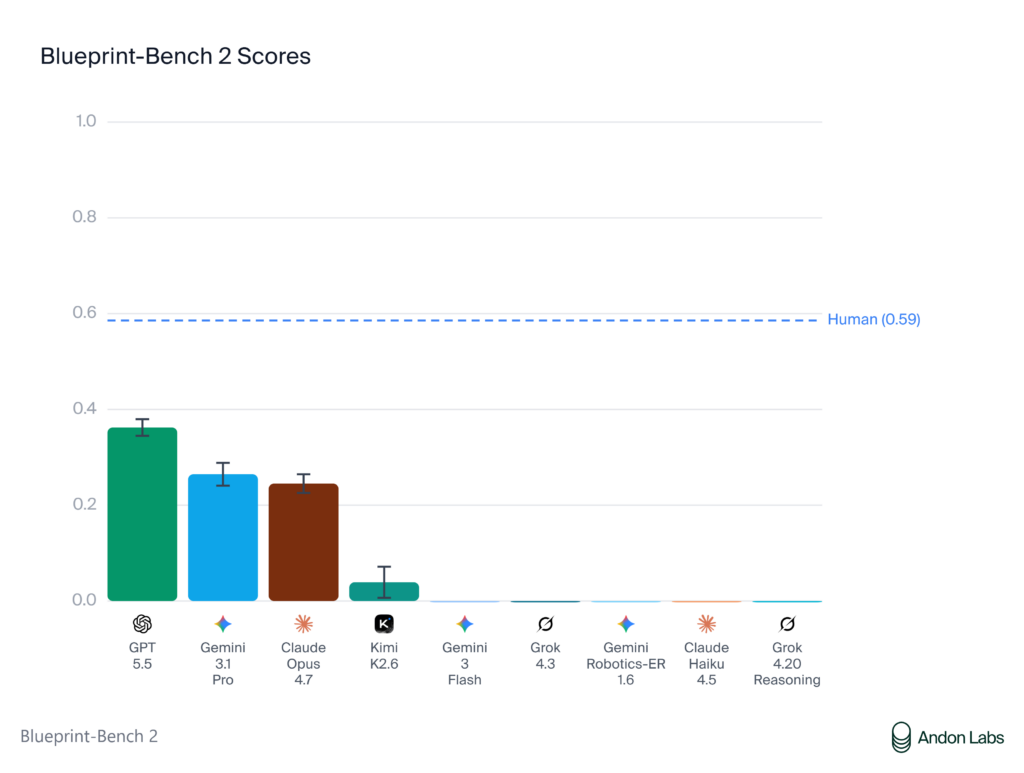
Seven months ago, every model on Blueprint-Bench scored at random baseline. The second version of the benchmark shows the first real signs of spatial reasoning from AI, with GPT 5.5 leading the leaderboard at 0.362 against a human score of 0.586.

Andon Labs just released Blueprint-Bench 2, a spatial reasoning benchmark that asks AI agents to convert apartment photographs into accurate 2D floor plans. When the original benchmark ran seven months ago, every model scored at or below random baseline. The results are different this time.
The task is harder than it sounds. Each agent examines around 20 interior photos of an apartment and has to produce a floor plan showing room layouts, connections, and relative sizes. Getting the room count right is straightforward. Figuring out which rooms connect to which is not.
The leaderboard:
- GPT 5.5: 0.362
- Gemini 3.1 Pro: 0.265
- Claude Opus 4.7: 0.245
- Kimi K2.6: 0.039
- Human baseline: 0.586
Six of the ten models tested scored at or below random baseline, meaning they performed no better than a random guess at room connectivity. The top three pulled clearly ahead of the rest, with tight variance across all 50 apartments, which Andon Labs reads as consistent spatial reasoning rather than lucky outputs.
The scoring is weighted heavily toward room-to-room connectivity. Jaccard similarity, which measures overlap in which rooms connect to which, accounts for 50% of the composite score. Nearly all models get room count right at around 90%, but that alone doesn’t move the needle.
The benchmark includes a persistent notepad system that carries across all 50 apartments. Agents can record patterns and refine their approach as they go. The top models used this to build structured knowledge about typical apartment layouts over the course of the eval.
Andon Labs published two examples of reasoning that didn’t exist in the original benchmark. Gemini 3.1 Pro identified a washer/dryer visible in two separate photos and used it as a directional landmark to figure out which way the camera was facing. GPT 5.5 noticed that a single bedroom appeared to have doors leading to two different rooms across two separate photos, and correctly inferred it was functioning as a through-room connecting the living area and the hall.
Neither of those is a pattern-match. Both require inferring spatial relationships from incomplete visual information across multiple images.
Suggested bottom line: Seven months ago this benchmark produced noise. Now three frontier models are showing consistent spatial reasoning from photographs. The gap to human performance is still large, but the direction of travel is clear, and the applications in robotics and physical AI are obvious.
Source: Andon Labs
Get the core business tech news delivered straight to your inbox. We track AI, automation, SaaS, and cybersecurity so you don't have to.
Just read what you want, and be done with it.