Users report declining quality on Z.ai’s GLM-5 coding plans
GLM-5 arrived as one of the most compelling budget alternatives to frontier coding models. Users on Reddit are now reporting the quality is quietly getting worse.
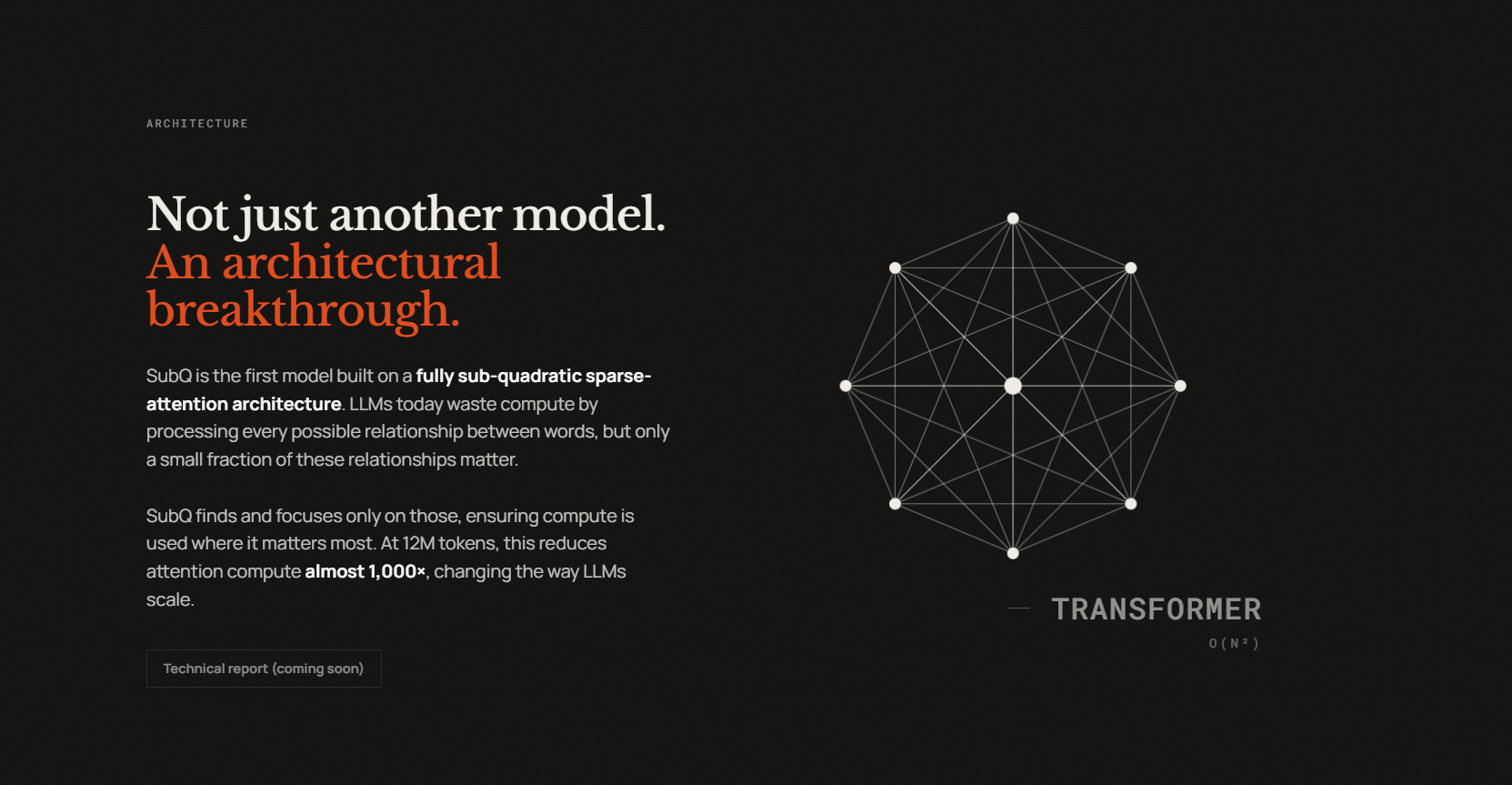
GLM-5 from Zhipu AI made a strong entrance earlier this year, posting benchmark numbers that put it in the same conversation as Claude Opus on coding and agentic tasks.
Z.ai’s coding plans built on that reputation, offering high-volume API access at a fraction of what Claude or GPT-5 cost. For a while, it looked like one of the better deals in the AI tools space.
That reputation is taking some hits on Reddit.
A thread on r/ZaiGLM titled “Don’t buy GLM coding plans. Quality is atrocious. It’s becoming worse everyday” has sparked a broader discussion among users of Z.ai’s Max plan.
The complaints center on a specific pattern: quality that was acceptable at launch appears to have degraded after recent infrastructure changes Z.ai described as performance improvements.
- The specific complaints: Worse instruction following than previous GLM versions, thinking time that feels artificially shortened, outputs that some users describe as resembling a quantized or degraded model.
- The context window issue: Several users report noticeable quality drops beyond 80-100k tokens.
- The frustration: Users on the Max plan are paying premium prices for what feels like a worse product than the cheaper tiers delivered months ago.
It is worth being clear about what this is and what it is not. These are Reddit complaints, not verified performance data. Sentiment on r/ZaiGLM is genuinely polarized — plenty of developers report solid results using GLM-5 for lighter coding tasks, frontend work, and high-volume workflows where cost matters more than raw capability.
The complaints are concentrated among users pushing GLM-5 on complex, long-horizon agentic tasks — exactly the use case Z.ai’s Max plan is marketed for.
The Bottom Line: Cheap frontier-adjacent AI is only a good deal if the quality holds.
Get the core business tech news delivered straight to your inbox. We track AI, automation, SaaS, and cybersecurity so you don't have to.
Just read what you want, and be done with it.