Fish Audio’s new STT tool turns transcripts into production-ready voice scripts
Fish Audio launched a speech-to-text tool that automatically tags emotions and speaker turns inline, with output designed to feed directly into its S2 Pro text-to-speech model.
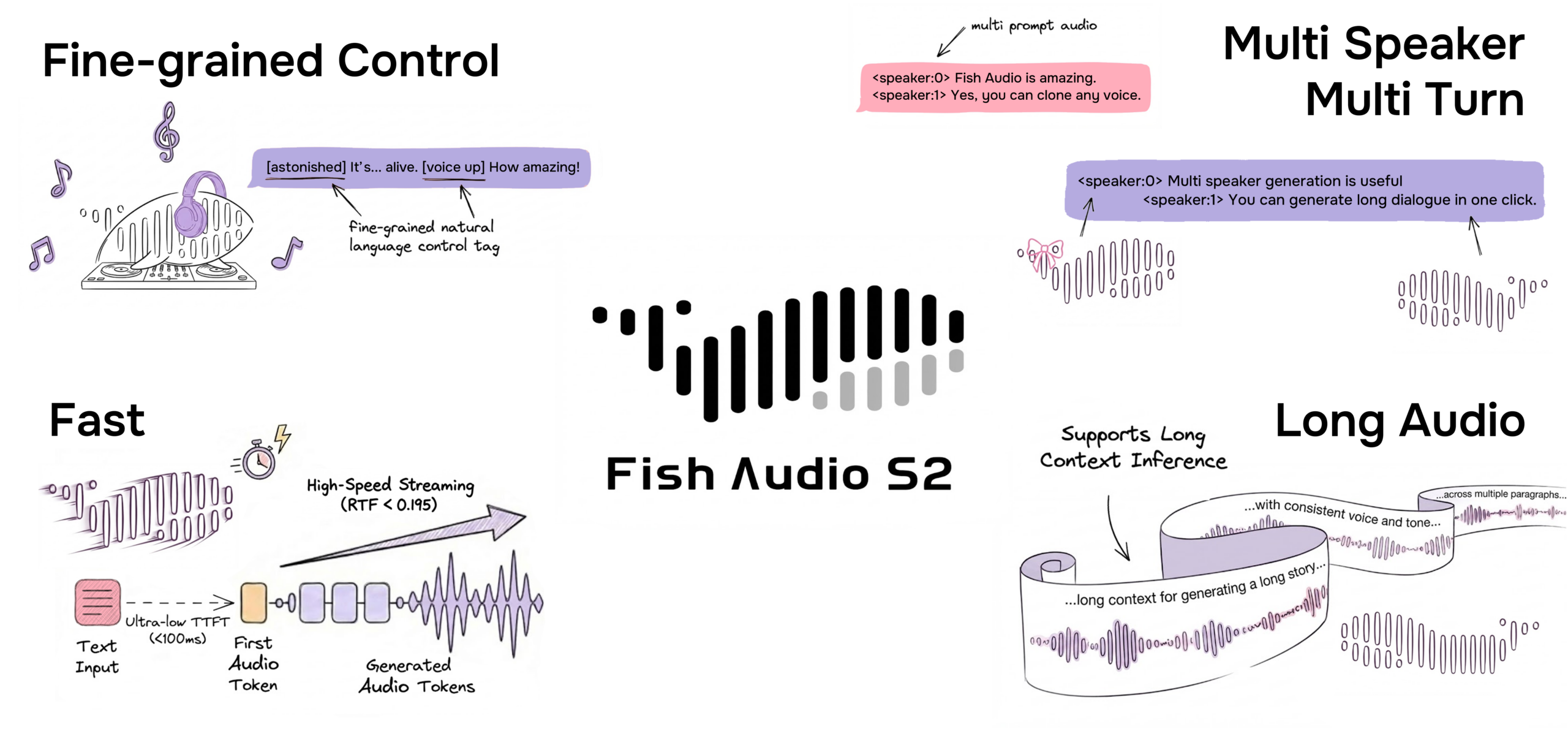
Fish Audio launched a speech-to-text tool this week, adding the other half of a voice production pipeline to a platform that already has one of the better open-source TTS models available.
The STT tool isn’t built for generic transcription. It’s designed specifically for podcast, interview, and conversational audio workflows, and its most interesting feature is what it does with the output.
How it works: The tool automatically inserts emotion and paralanguage tags inline at the exact moment they occur in the audio. Tags like [laugh], [sigh], [pause], and [breath] appear directly in the transcript. These match the exact tag format used by S2 Pro, which means a raw transcript can go straight into voice generation without any reformatting.
- The speaker detection: Automatically labels speakers in multi-speaker recordings. You can set the speaker count manually for better accuracy.
- The language support: 100+ languages with automatic code-switching for multilingual audio.
- The export formats: SRT, VTT, and JSON, with options to include or exclude emotion tags, speaker labels, and punctuation.
The pricing: A free tier covers 8,000 credits per month, roughly 26 minutes of audio. Paid plans add more credits at around 300 credits per minute.
The bigger picture: The oldest complaint about text-to-speech is that it sounds robotic. Fish Audio is trying to fix that from both ends. S2 Pro injects emotion into generated speech, and now the STT tool captures it from real audio.
Try Fish STT.
Get the core business tech news delivered straight to your inbox. We track AI, automation, SaaS, and cybersecurity so you don't have to.
Just read what you want, and be done with it.